Getting started tutorial part 7: analyzing measurement catalogs in multiple bands¶
In this part of the tutorial series you’ll analyze the forced photometry measurement catalogs you created in step 6. You’ll learn how to work with measurement tables and plot color-magnitude diagrams (CMDs).
Set up¶
Pick up your shell session where you left off in part 6. For convenience, start in the top directory of the example git repository.
cd $RC2_SUBSET_DIR
The lsst_distrib package also needs to be set up in your shell environment.
See Setting up installed LSST Science Pipelines for details on doing this.
As in part 3, you’ll be working inside an interactive Python session for this tutorial. You can use the default Python shell (python), the IPython shell, or even run from a Jupyter Notebook. Ensure that this Python session is running from the shell where you ran setup lsst_distrib.
Loading forced photometry measurement catalogs with the Butler¶
The forced_objects pipeline (Running forced photometry on coadds) created deepCoadd_forced_src datasets for each coadd in the example data repository.
Being forced photometry catalogs, rows in each deepCoadd_forced_src table correspond row-for-row across all coadds in different filters for a skymap patch.
Since you don’t have to do additional cross-matching, these deepCoadd_forced_src datasets are convenient.
To get these datasets, open a Python session (IPython or Jupyter Notebook) and create a Butler. When generating the datasets, you put them into specific collections. We need to specify the collections to the butler, so it knows where to look for the data you are going to be requesting:
import os
from lsst.daf.butler import Butler
collections = [f"u/{os.environ['USER']}/objects", f"u/{os.environ['USER']}/coadd_meas"]
butler = Butler('SMALL_HSC', collections=collections)
This Butler is using the coaddForcedPhot collection you created for the forced_objects pipeline outputs.
Next, use the Butler to get the deepCoadd_forced_src datasets for both filters:
gSources = butler.get('deepCoadd_forced_src', band='g', tract=9813, patch=41)
rSources = butler.get('deepCoadd_forced_src', band='r', tract=9813, patch=41)
iSources = butler.get('deepCoadd_forced_src', band='i', tract=9813, patch=41)
These datasets correspond to coadds for a single patch (41 in tract 9813) for both the HSC-G, HSC-R and HSC-I filters.
Getting calibrated PSF photometry¶
The base_PsfFlux_instFlux column of these deepCoadd_forced_src datasets is the instrumental flux from the linear least-squares fit of the PSF model to the source.
From the source table’s schema you know this flux has units of counts:
iSources.getSchema().find('base_PsfFlux_instFlux').field.getUnits()
Transforming this instrumental flux into a magnitude requires knowing the coadd’s photometric calibration, which you can get from the coadd dataset.
The coadd you made in part 5 with the assembleCoadd pipeline doesn’t have calibration info attached to it, though.
Instead, you want the deepCoadd_calexp dataset, which was created by the coadd_measurement pipeline, because it does have calibrations.
You can access these calibrations directly from deepCoadd_calexp.photoCalib datasets for each filter:
gCoaddPhotoCalib = butler.get('deepCoadd_calexp.photoCalib', band='g', tract=9813, patch=41)
rCoaddPhotoCalib = butler.get('deepCoadd_calexp.photoCalib', band='r', tract=9813, patch=41)
iCoaddPhotoCalib = butler.get('deepCoadd_calexp.photoCalib', band='i', tract=9813, patch=41)
Note
An alternative way to get the lsst.afw.image.PhotoCalib object is from the deepCoadd_calexp dataset object:
rCoaddCalexp = butler.get('deepCoadd_calexp', band='r', tract=9813, patch=41)
rCoaddPhotoCalib = rCoaddCalexp.getPhotoCalib()
Note that this method is slower than getting just the photoCalib component and should only be used if you intend to use the calexp later on.
These PhotoCalib objects not only have methods for directly accessing calibration information, but also for applying those calibrations.
Use the PhotoCalib.instFluxToMagnitude() method to transform instrumental fluxes in counts to AB magnitudes, and PhotoCalib.instFluxToNanojansky() to transform counts into nanojansky.
When called with an lsst.afw.table.SourceCatalog and string specifying the flux field name, these methods each return an array with the magnitude and magnitude error as a list of tuples.
gMags = gCoaddPhotoCalib.instFluxToMagnitude(gSources, 'base_PsfFlux')
rMags = rCoaddPhotoCalib.instFluxToMagnitude(rSources, 'base_PsfFlux')
iMags = iCoaddPhotoCalib.instFluxToMagnitude(iSources, 'base_PsfFlux')
Filtering for unique, deblended sources with the detect_isPrimary flag¶
Before going ahead and plotting a CMD from the full source table, you’ll typically need to do some basic filtering. Exactly what filtering is done depends on the application, but source tables should always be filtered for unique sources. There are two ways that measured sources might not be unique: deblended sources and sources in patch overlaps. Additionally, some sources are “sky” objects added by the coadd measurement step for noise characterization that you need to filter out. This section gives a brief introduction to removing duplicate and unwanted sources, for details see Deblending Flags Overview.
Finding deblended sources¶
When objects are detected, they are deblended.
Deblending involves decomposing a source into multiple child sources that have local flux peaks.
In source tables like rSources and iSources, both the original (blended) and de-blended sources are included in the table.
This is done so that you can choose whether to use blended or deblended measurements in your analysis.
If you don’t choose, though, the same flux will be included multiple times in your analysis.
Usually you will want to use fully-deblended sources in your analysis.
You can tell which sources are deblended by the fact that they have no children.
This is held in the deblend_nChild column.
Simply look for records where this value is zero.
All source catalogs come from the same deblending run, so you can use any band to build the mask array.
isDeblended = rSources['deblend_nChild'] == 0
Finding primary detections¶
The other reason a source in the table might not be unique is if it falls in the overlaps of patches. Sources in overlaps appear in multiple measurement tables.
If you are analyzing multiple patches, or multiple tracts, you want to use the primary detection for each source. The Pipelines determine if a detection in a patch is primary, or not, by whether it falls in the inner region of that patch (and tract). An inner region is a part of a skymap exclusively claimed by one patch.
The flag that indicates whether a source lies in the patch’s inner region isn’t in the deepCoadd_forced_src table though.
Instead, you need to look at the deepCoadd_ref table made as part of the coadd_measurement pipeline in the previous tutorial.
Begin by using the Butler to get the deepCoadd_ref dataset for patch you’re analyzingL
refTable = butler.get('deepCoadd_ref', tract=9813, patch=41)
Then make an index array from the combination of detect_isPatchInner and detect_isTractInner flags:
inInnerRegions = refTable['detect_isPatchInner'] & refTable['detect_isTractInner']
Rejecting sky objects¶
Coadd measurement is configured, by default, to add “sky” objects to the catalog. These “sky” objects do not correspond to detections but are used for characterizing the image’s noise properties.
The merge_peak_sky flag identifies these “sky” objects:
isSkyObject = refTable['merge_peak_sky']
You will want to reject these if you are only interested in real sources.
The go-to flag: detect_isPrimary¶
You actually want the combination of the isDeblended, inInnerRegions , and isSkyObject arrays you just made.
The deepCoadd_ref table provides a shortcut for this: the detect_isPrimary flag identifies sources that are both fully deblended and in inner regions.
Run:
isPrimary = refTable['detect_isPrimary']
Now you can use this array to slice the photometry arrays and get only primary sources, like this:
gMags[isPrimary]
rMags[isPrimary]
iMags[isPrimary]
Note
The detect_isPrimary flag is defined by this algorithm:
(deblend_nChild == 0) & detect_isPatchInner & detect_isTractInner & (merge_peak_sky == False)
Tip
You can learn about any table column from the schema. For example:
refTable.schema.find('detect_isPrimary')
You can get a list of all columns available in a table by running:
refTable.schema.getNames()
Quickly classifying stars and galaxies¶
Reliably classifying sources as stars and galaxies is not easy, but you can get a rough estimate based on the extendedness of sources.
The base_ClassificationExtendedness_value column is 1. for extended sources (galaxies) and 0. for point sources (like stars).
To see this for yourself, run:
iSources.schema.find('base_ClassificationExtendedness_value').field.getDoc()
Go ahead and create a boolean indexes of sources classified as point sources and extended sources in the i-band:
isStellar = iSources['base_ClassificationExtendedness_value'] < 1.
isExtended = iSources['base_ClassificationExtendedness_value'] == 1.
Using measurement flags¶
Lastly, you may want to work with only high-quality measurements.
Earlier, you got PSF fluxes of sources (base_PsfFlux_instFlux).
The base_PsfFlux measurement plugin also creates flags that describe measurement errors and issues.
You can find these flags, as usual, from the table schema.
Here’s a way to find columns produced by the base_PsfFlux plugin:
iSources.getSchema().extract('base_PsfFlux_*')
A useful flag is base_PsfFlux_flag, which is the logical combination of specific base_PsfFlux error flags:
isGoodFlux = ~iSources['base_PsfFlux_flag'] & ~rSources['base_PsfFlux_flag'] & ~gSources['base_PsfFlux_flag']
Since the base_PsfFlux_flag is True for sources with measurement errors, you used the unary invert operator (~) so that well-measured sources are True in the isGoodFlux array.
We need to and together the sources flagged as good between both the r-band and i-band so that we know each source has both magnitudes.
Finally, combine all these boolean index arrays together:
selected_stellar = isPrimary & isStellar & isGoodFlux
selected_extended = isPrimary & isExtended & isGoodFlux
In the next step, you’ll plot a color-magnitude diagram of the sources you’ve selected.
Make a color-color diagram¶
The product of this effort will be an g-r/r-i color-color diagram showing both galaxies and stars. You can use matplotlib to create this visualization:
import matplotlib.pyplot as plt
# Grab just the magnitudes and ignore the errors for now
plt_gMags_stellar = [el[0] for el in gMags[selected_stellar]]
plt_rMags_stellar = [el[0] for el in rMags[selected_stellar]]
plt_iMags_stellar = [el[0] for el in iMags[selected_stellar]]
gmr_stellar = [el1 - el2 for el1, el2 in zip(plt_gMags_stellar, plt_rMags_stellar)]
rmi_stellar = [el1 - el2 for el1, el2 in zip(plt_rMags_stellar, plt_iMags_stellar)]
plt_gMags_extended = [el[0] for el in gMags[selected_extended]]
plt_rMags_extended = [el[0] for el in rMags[selected_extended]]
plt_iMags_extended = [el[0] for el in iMags[selected_extended]]
gmr_extended = [el1 - el2 for el1, el2 in zip(plt_gMags_extended, plt_rMags_extended)]
rmi_extended = [el1 - el2 for el1, el2 in zip(plt_rMags_extended, plt_iMags_extended)]
plt.style.use('seaborn-notebook')
plt.figure(1, figsize=(4, 4), dpi=140)
plt.scatter(gmr_stellar,
rmi_stellar,
edgecolors='None', s=4, c='k')
plt.scatter(gmr_extended,
rmi_extended, marker='v',
edgecolors='None', s=4, c='r')
plt.xlabel('$g-r$')
plt.ylabel('$r-i$')
plt.subplots_adjust(left=0.125, bottom=0.1)
plt.show()
You should see a figure like this:
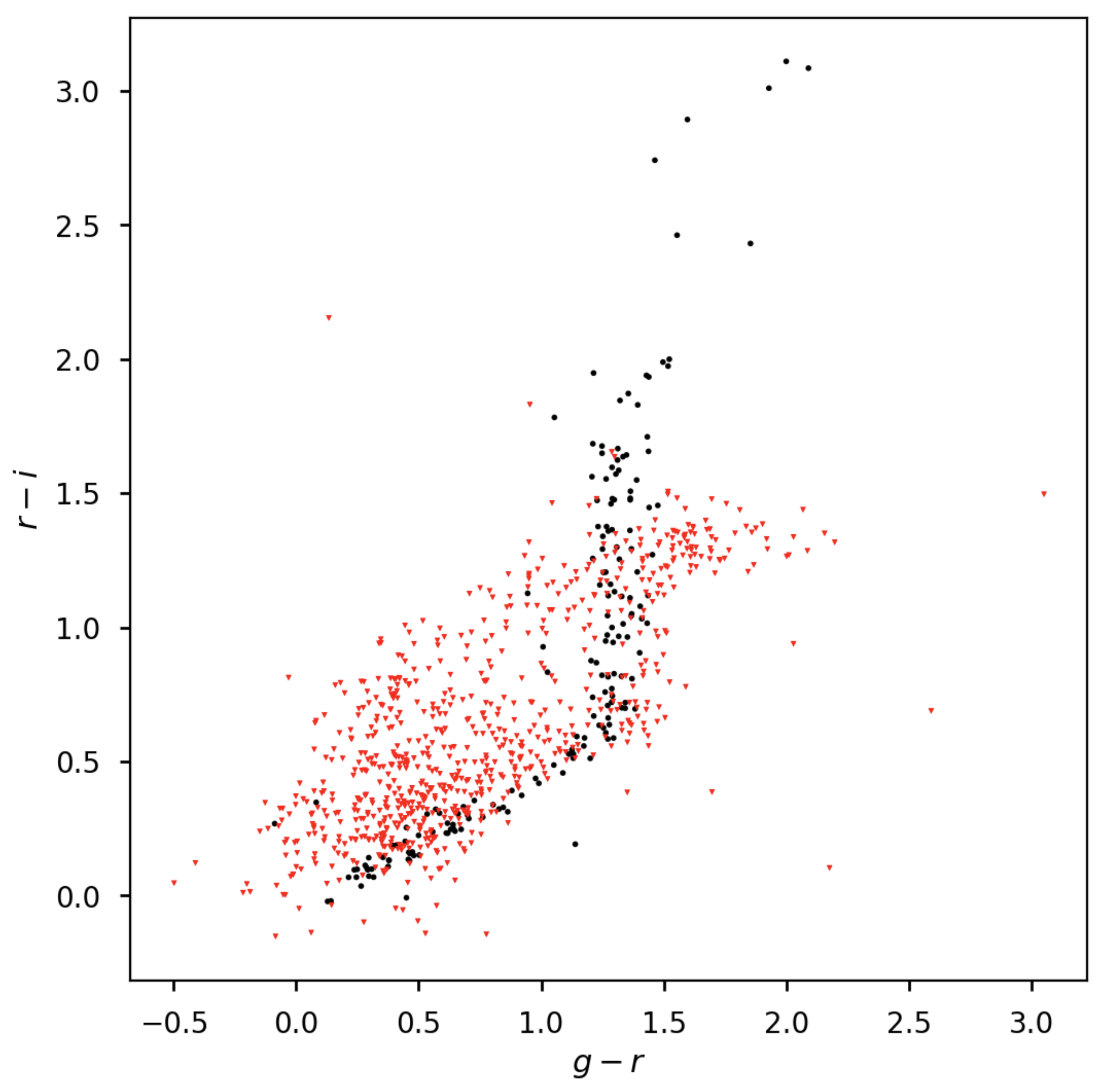
Figure 3 Color-color plot for stars and galaxies. Stars are plotted as black circles. Galaxies are plotted as red inverted triangles.¶
Wrap up¶
In this tutorial, you gained experience working with source measurement catalogs created by the LSST Science Pipelines. Here are some takeaways:
Forced photometry source tables are
deepCoadd_forced_srcdatasets. They’re convenient to use becausedeepCoadd_forced_srctables from different filters (for a given skymap patch) correspond row-for-row.You need to filter sources for uniqueness due to deblending and patch overlaps. The
detect_isPrimarycolumn from thedeepCoadd_refdataset is the go-to flag for doing this.Use the
base_ClassificationExtendedness_valuecolumn to quickly distinguish stars from galaxies.The
base_PsfFlux_flagcolumn is useful for identifying sources that don’t have photometric measurement errors.
In the end, you created a simple color-color diagram.
This tutorial is just the beginning, though.
With the dataset you’ve created in this tutorial, you can look at galaxies with measurements from the CModel plugin.
Or compare PSF-fitted photometric measurements with aperture photometry of stars.
When you’re ready, dive into the rest of the LSST Science Pipelines documentation to begin processing your own data. As you’re learning, don’t hesitate to reach out with questions on the LSST Community forum.